
cn
数据解决方案
请输入姓名
手机号码格式错误
请输入联系电话
请输入公司名称
请输入正确的工作邮箱
请输入数据需求
提交成功!感谢您支持数据堂。
填写格式错误请重新填写
确定
数据需求不能小于5个字且不能为纯数字
https://www.datatang.com
https://www.datatang.ai
m.datatang.ai
解决方案 | 数据堂垂域大模型数据服务能力解读
作者:数据堂 发布时间:2025-09-11
当前,在“人工智能+”行动背景下,垂直领域大模型的发展呈现出蓬勃态势。与通用大模型相比,垂域大模型的底层逻辑在于解决专业领域存在的“幻觉”、知识不准确、缺乏深度等痛点。而要实现这一点,核心在于数据:唯有注入海量、精准、合规的专业领域数据,模型才能模拟专家进行领域问题的深度思考,助力解决产业实际问题。
十五年来, 历经100+大模型数据服务项目,数据堂深刻洞察到:在大垂域模型时代,高质量的行业数据建设离不开专家标注人才及高度成熟的数据生产团队。
我们将从垂域数据服务资源、垂域成品数据集以及典型案例三个维度,展示数据堂如何为客户高效、专业提供垂域大模型数据解决方案。

多行业服务能力:标注人才资源与专业优势
数据堂已建立覆盖学科竞赛、编程、金融、医疗、法律、教育、多模态大模型等多个垂直领域的专业数据资源团队,总数超500+。每支团队均由数据堂分级管理,配备充足的一线标注人员及候补资源,能够快速响应各类垂域大模型数据需求。且团队规模持续扩展,确保在面对大型项目及紧急需求时具备高效承接和快速交付能力,为客户提供稳定可靠的数据服务支持。
其中,一线的标注员均具备相关专业背景、学位及相关证书并具备大模型项目经验,能精准把握数据需求,高效构建高质量行业数据集:
- 金融领域
团队由金融、经济、投资等专业人才组成,核心成员具备理财与投资顾问经验,部分来自一线证券经纪业务转型人员。团队擅长处理金融实体关系识别、风险参数标注、经济指标关联性分析等专业任务,确保风控模型和投资决策数据的精准性。
- 医疗领域
团队全部来自临床医学、中西医临床医学、中医学、医学影像学等专业,均完成系统医学专业课学习,核心成员具备1-3年临床实践经验。团队专注于医疗影像标注、疾病诊断数据标注、医学术语标准化等任务,标注结果达到临床诊断应用级别。

- 法律领域
团队由通过法律职业资格考试的专业人员构成,研究方向覆盖劳动人事、婚姻继承、交通事故、房产物业纠纷、经济纠纷等多个领域。擅长法律条文解析、案例要点标注、法律关系梳理等专业任务,确保法律语义理解的准确性。
- 教育学科领域
团队由汉语言文学、数理化等学科专业人才组成,成员具备学科教学经验和竞赛指导背景。能够处理学科知识图谱构建、竞赛试题解析、推理过程标注等复杂任务,准确理解各学科专业知识体系和教学要求。
- 3D与美学领域
团队来自3D美术、视觉传达设计、动画设计等专业,熟练掌握Blender、UE、Unity等专业工具,具备模型构建、纹理处理、光影渲染等专业技能。团队专注3D模型标注、美学质量评估、视觉要素标注等任务,满足高质量多媒体数据需求。
- 代码编程领域
团队由计算机科学、软件工程、电子信息工程等专业人才组成,熟悉多种编程语言和开发框架,具备扎实的算法基础和逻辑分析能力。擅长代码生成、算法推理、技术文档标注等专业任务,确保编程相关数据的技术准确性。

- 新型垂直领域
团队还包含游戏设计、音乐工程、影视编剧等特色领域人才,成员均具备相关专业背景和行业经验,能够满足AI生成内容、娱乐应用等新兴领域的多样化数据需求。
即买即用:基于专业标注的标准化数据集产品
在垂域大模型的训练过程中,企业往往面临 “需求明确,但缺乏现成数据” 的困境。为助力客户快速落地大模型,数据堂开发覆盖10+类垂域大模型、量级达PB级别的成品数据,可直接用于模型训练与评测。
- 医疗大模型数据
涵盖常用医学知识库、医疗类问答解析数据、医疗类文章及专业试题文本数据。包括中英等语种。内容覆盖药物、疾病、诊断、术后等全阶段,涉及疾病、药物、诊断、检查、护理等相关的医学专业知识。
- 教育大模型数据
数据类别涵盖图像、文本及多模态。其中,文本数据包括课件、试题等覆盖小学至大学、研究生、博士阶段的知识。图像数据包括拍照解题数据、试题数据。多模态数据为多学科多模态理解推理数据。语种涵盖中文、英文、韩语等。

- 金融大模型数据
总量达800万,包括金融类试题文本结构化解析处理数据、法律法规试题库等垂直领域文本解析数据。数据均为JSON格式,涵盖标题、发布部门、发布日期、内容等字段。
- 法律大模型数据
包含千万级别法律法规解析化数据、问答数据等。内容覆盖法律法规、司法解释、规章制度及各级规定等。数据堂严格依据法律行业的数据合规标准,为法律智能检索、合同审查、法律咨询等应用提供坚实的数据支撑。
- 政务大模型数据
中文政务文本数据,本数据包含不同省、市、县级的政策文件、政策解读、公告、新闻、问答5个类别。该数据可用于政务大模型训练。
案例详解:数据堂如何打出组合拳
1. 数学文本结构化解析题库数据标注
对小学、初中、高中、大学及数学竞赛题库进行系统化、结构化的深度解析,涵盖代数、几何等多种题型。标注人员需具备扎实的数学专业基础及出色的信息归纳与总结能力。

项目挑战与应对策略
a) 标注需具备扎实的数学专业基础,人员门槛高
✓ 通过严格筛选机制,从现有专家库中遴选出具备深厚数学知识且有丰富大模型标注经验的专业人员。
b) 要求所有操作过程中设置权限管理,保障数据安全
✓ 采用“专家带队+多层权限管理”模式,严格分配不同级别数据访问和操作权限。通过定期审计分析及时处理异常操作,并根据项目进展和数据安全需求及时调整权限设置。
项目成果
最终交付数据通过率95%以上,一次性验收合格,支撑客户教育大模型高质量训练需求。
2. 法律政务类大模型评测与优化
对法律咨询、政务问答及公文生成类大模型输出进行多维度评测与优化,涵盖专业性、准确性与合规性,提升模型在垂直领域的实用性与可靠性。
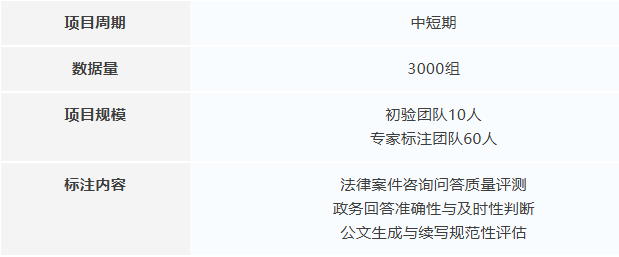
项目挑战与应对策略
a) 项目工期紧、任务重,且要求标注人员具备法律、政务等专业背景
✓ 通过线上线下多渠道紧急招募具有律师、政务文书经验的专业人员,建立高合规性标注团队。
b) 公文类任务主观性强,验收通过率低
✓ 整理强主观性样例多次对齐标准,设置初验-标注点对点验收机制,加强质量闭环。
项目成果
项目在紧急周期内高质量交付,有效支持客户大模型在法律、政务领域的优化迭代,整体验收通过率符合预期。
今后,大模型应用领域将不断拓展,面临的挑战也会更加复杂多样。未来,数据堂将以更多的高质量、多领域、经验丰富的人才团队,为客户制定个性化的数据解决方案,助力每一条数据释放最大价值,让每一个大模型都能跑得更快、更稳、更远。
近期内容
 更高质量的数据 更有竞争力的AI
更高质量的数据 更有竞争力的AI
- 联系我们
 13051623904
13051623904 services@datatang.com
services@datatang.com-




